Transformers
-

How to implement a new generation of transformer recommenders
35 min read -

“Attention is All you Need” showed attention as a sequence of multiplicative and concat operations…
8 min read -

Why working memory is a more important bottleneck than raw context window size
9 min read -

This is how to use the attention mechanism in a time series classification framework
9 min read -

The workflow Of tensors Inside Transformers
4 min read -

Adapting CLIP to YouTube Data (with Python Code)
10 min read -

Find out how Flash Attention works. Afterward, we’ll refine our understanding by writing a GPU…
7 min read -
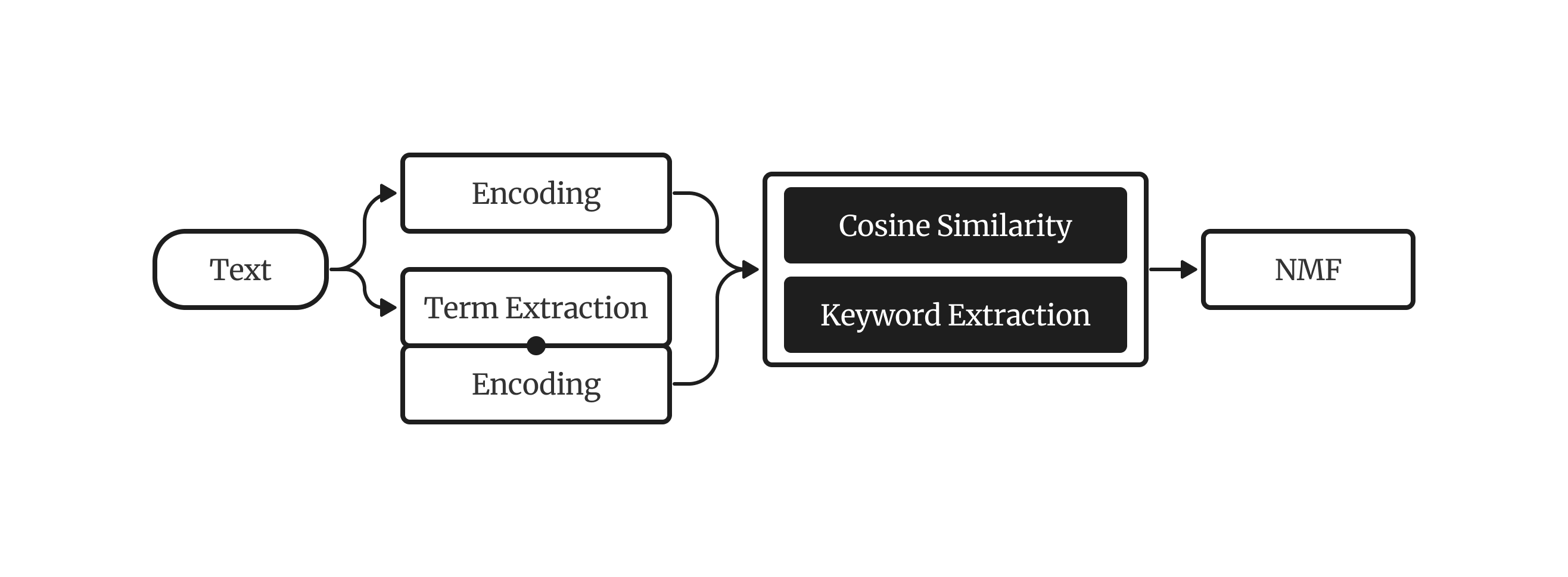
A comprehensive guide on getting the most out of your Chinese topic models, from preprocessing…
8 min read -

Examples of custom callbacks and custom fine-tuning code from different libraries
8 min read -

Transforming the Math of the Transformer Model
9 min read