One day, a data scientist told that Ridge Regression was a complicated model. Because he saw that the training formula is more complicated.
Well, this is exactly the objective of my Machine Learning “Advent Calendar”, to clarify this kind of complexity.
So, in today’s article, we will talk about penalized versions of linear regression.
- First, we will see why the regularization or penalization is necessary, and we will see how the model is modified
- Then we will explore different types of regularization and their effects.
- We will also train the model with regularization and test different hyperparameters.
- We will also ask a further question about how to weight the weights in the penalization term. (confused ? You will see)
Linear regression and its “conditions”
When we talk about linear regression, people often mention that some conditions should be satisfied.
You may have heard statements like:
- the residuals should be Gaussian (it is sometimes confused with the target being Gaussian, which is false)
- the explanatory variables should not be collinear
In classical statistics, these conditions are required for inference. In machine learning, the focus is on prediction, so these assumptions are less central, but the underlying issues still exist.
Here, we will see an example of two features being collinear, and let’s make them completely equal.
And we have the relationship: y = x1 + x2, and x1 = x2
I know that if they are completely equal, we can just do: y=2*x1. But the idea is to say they can be very similar, and we can always build a model using them, right?
Then what is the problem?
When features are perfectly collinear, the solution is not unique. Here is an example in the screenshot below.
y = 10000*x1 – 9998*x2
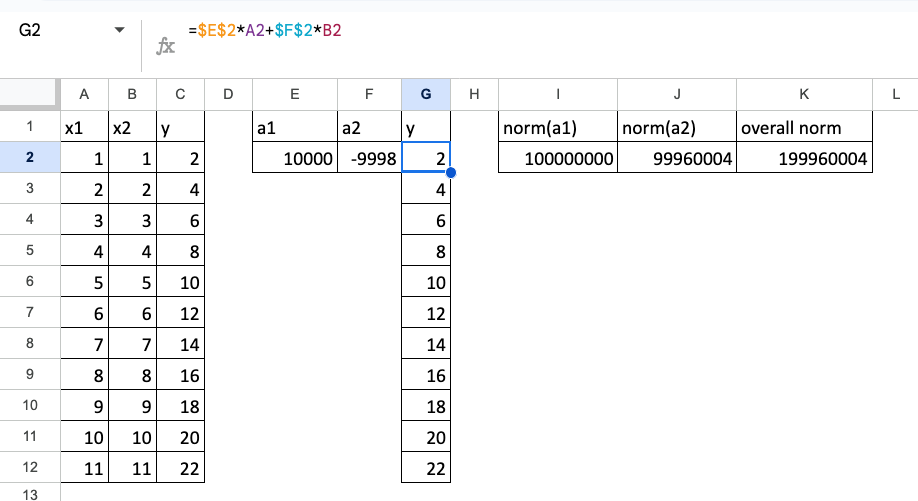
And we can notice that the norm of the coefficients is huge.
So, the idea is to limit the norm of the coefficients.
And after applying the regularization, the conceptual model is the same!
That is right. The parameters of the linear regression are changed. But the model is the same.
Different Versions of Regularization
So the idea is to combine the MSE and the norm of the coefficients.
Instead of just minimizing the MSE, we try to minimize the sum of the two terms.
Which norm? We can do with norm L1, L2, or even combine them.
There are three classical ways to do this, and the corresponding model names.
Ridge regression (L2 penalty)
Ridge regression adds a penalty on the squared values of the coefficients.
Intuitively:
- large coefficients are heavily penalized (because of the square)
- coefficients are pushed toward zero
- but they never become exactly zero
Effect:
- all features remain in the model
- coefficients are smoother and more stable
- very effective against collinearity
Ridge shrinks, but does not select.

Lasso regression (L1 penalty)
Lasso uses a different penalty: the absolute value of the coefficients.
This small change has a big consequence.
With Lasso:
- some coefficients can become exactly zero
- the model automatically ignores some features
This is why LASSO is called so, because it stands for Least Absolute Shrinkage and Selection Operator.
- Operator: it refers to the regularization operator added to the loss function
- Least: it is derived from a least-squares regression framework
- Absolute: it uses the absolute value of the coefficients (L1 norm)
- Shrinkage: it shrinks coefficients toward zero
- Selection: it can set some coefficients exactly to zero, performing feature selection
Important nuance:
- we can say that the model still has the same number of coefficients
- but some of them are forced to zero during training
The model form is unchanged, but Lasso effectively removes features by driving coefficients to zero.

3. Elastic Net (L1 + L2)
Elastic Net is a combination of Ridge and Lasso.
It uses:
- an L1 penalty (like Lasso)
- and an L2 penalty (like Ridge)
Why combine them?
Because:
- Lasso can be unstable when features are highly correlated
- Ridge handles collinearity well but does not select features
Elastic Net gives a balance between:
- stability
- shrinkage
- sparsity
It is often the most practical choice in real datasets.
What really changes: model, training, tuning
Let us look at this from a Machine Learning point of view.
The model does not really change
For the model, for all the regularized versions, we still write:
y =a x + b.
- Same number of coefficients
- Same prediction formula
- But, the coefficients will be different.
From a certain perspective, Ridge, Lasso, and Elastic Net are not different models.
The training principle is also the same
We still:
- define a loss function
- minimize it
- compute gradients
- update coefficients
The only difference is:
- the loss function now includes a penalty term
That is it.
The hyperparameters are added (this is the real difference)
For Linear regression, we do not have the control of the “complexity” of the model.
- Standard linear regression: no hyperparameter
- Ridge: one hyperparameter (lambda)
- Lasso: one hyperparameter (lambda)
- Elastic Net: two hyperparameters
- one for overall regularization strength
- one to balance L1 vs L2
So:
- standard linear regression does not need tuning
- penalized regressions do
This is why standard linear regression is often seen as “not really Machine Learning”, while regularized versions clearly are.
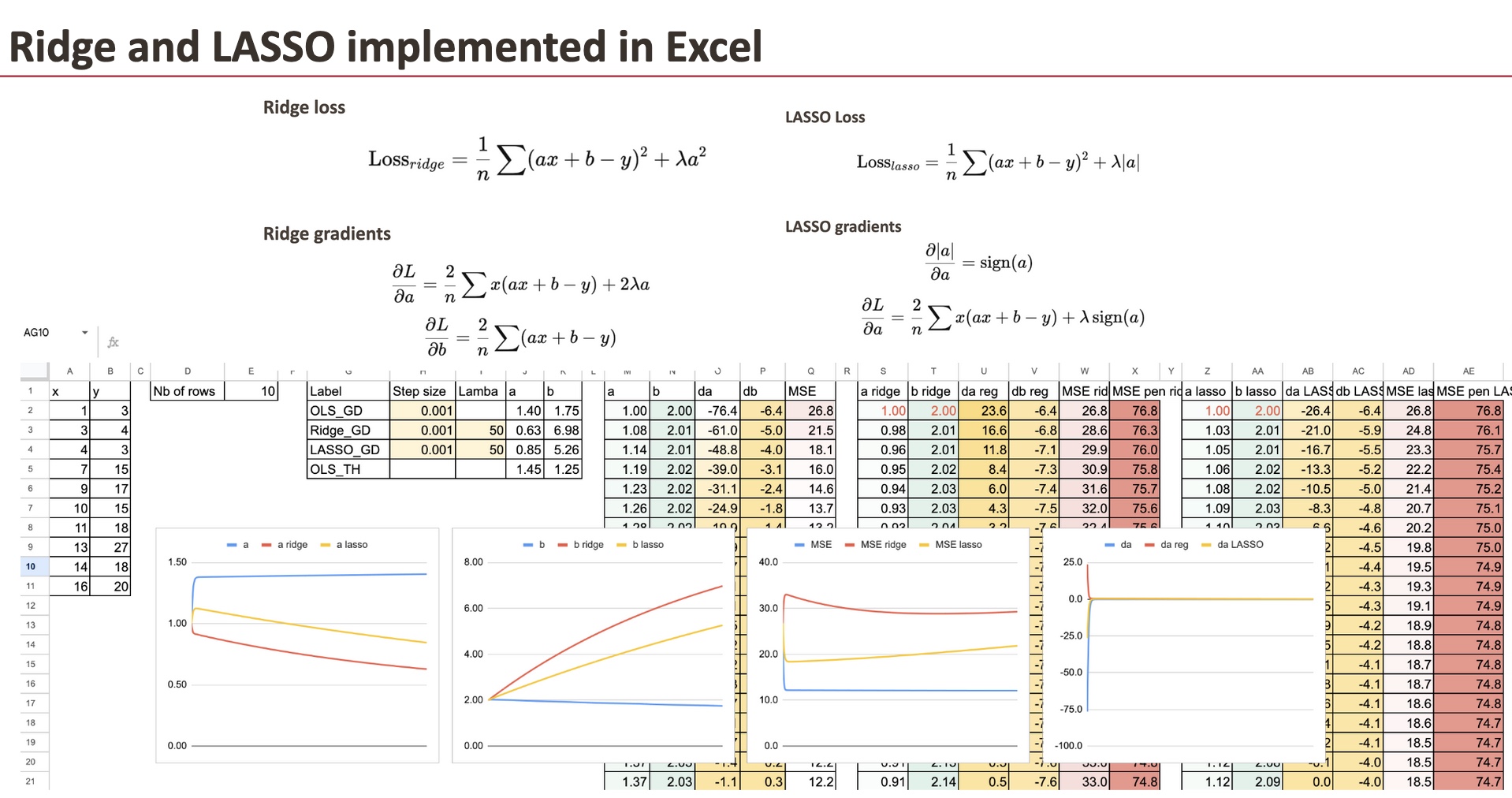
Implementation of Regularized gradients
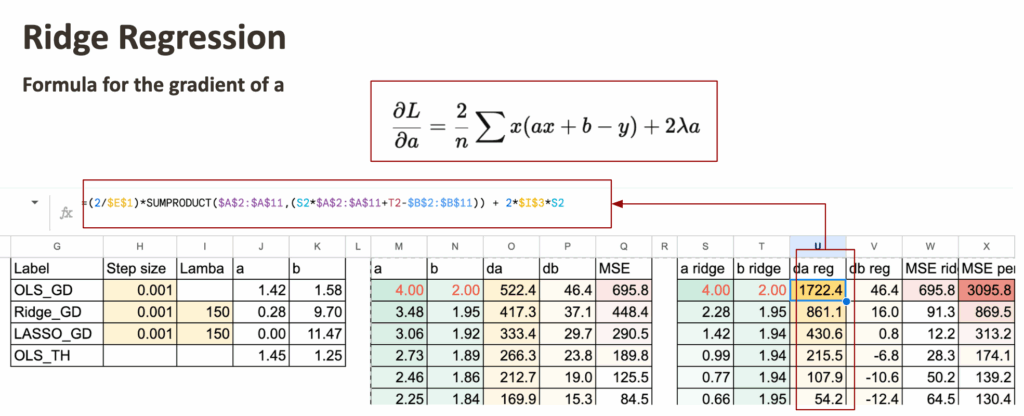
We keep the gradient descent of OLS regression as reference, and for Ridge regression, we only have to add the regularization term for the coefficient.
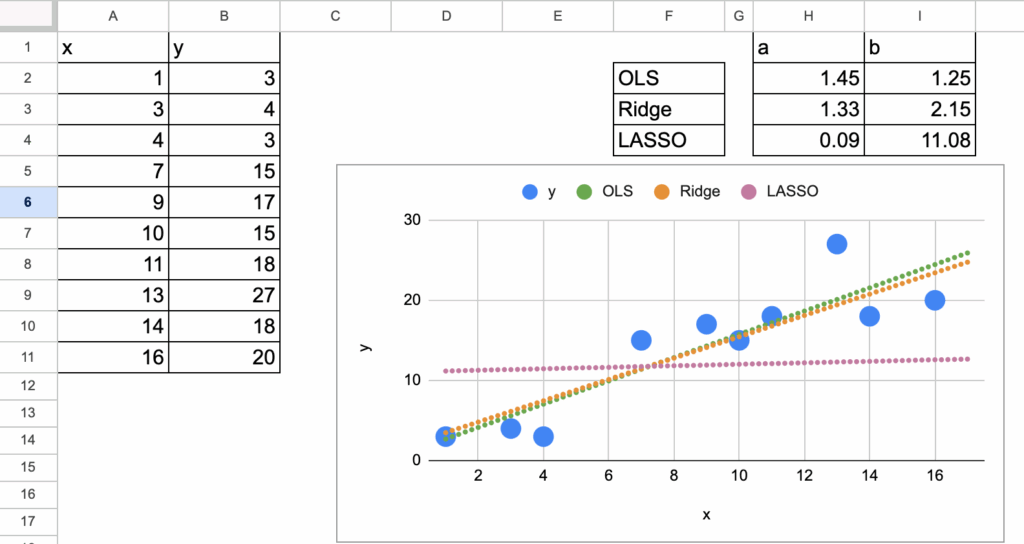
We will use a simple dataset that I generated (the same one we already used for Linear Regression).
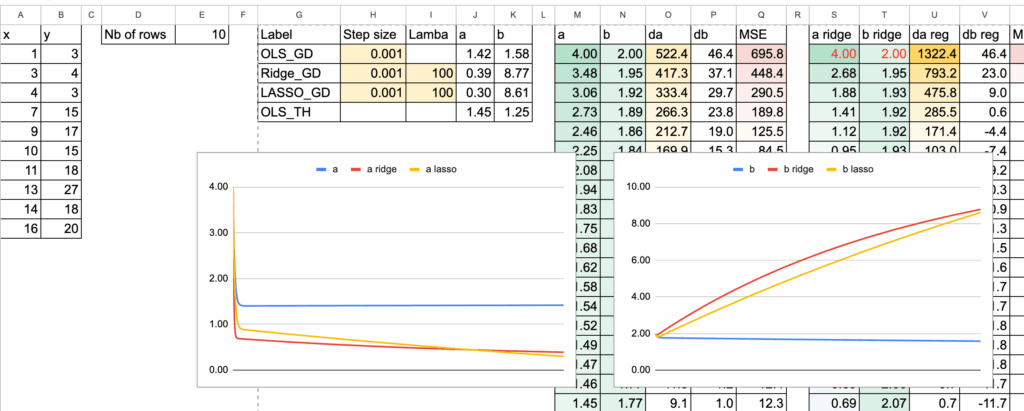
We can see the 3 “models” differ in terms of coefficients. And the goal in this chapter is to implement the gradient for all the models and compare them.
Ridge with penalized gradient
First, we can do for Ridge, and we only have to change the gradient of a.
Now, it does not mean that the value b is not changed, since the gradient of b is each step depends also on a.
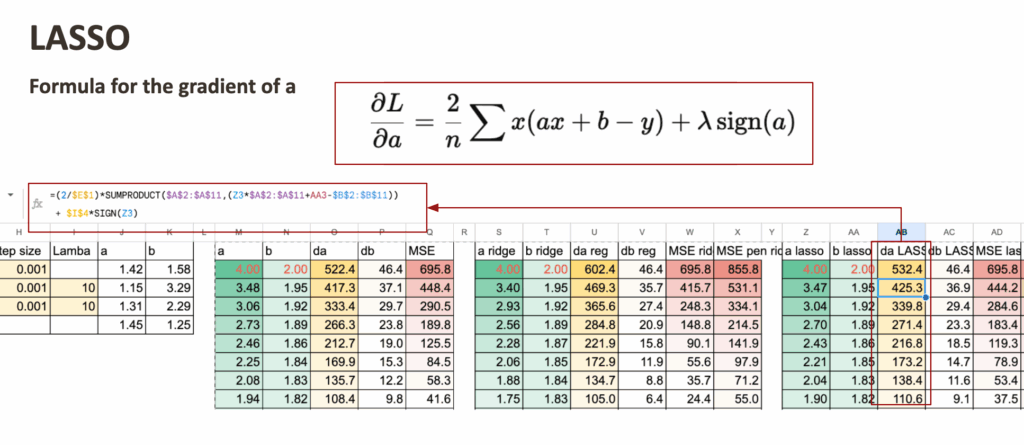
LASSO with penalized gradient
Then we can do the same for LASSO.
And the only difference is also the gradient of a.
For each model, we can also calculate the MSE and the regularized MSE. It is quite satisfying to see how they decrease over the iterations.
Comparison of the coefficients
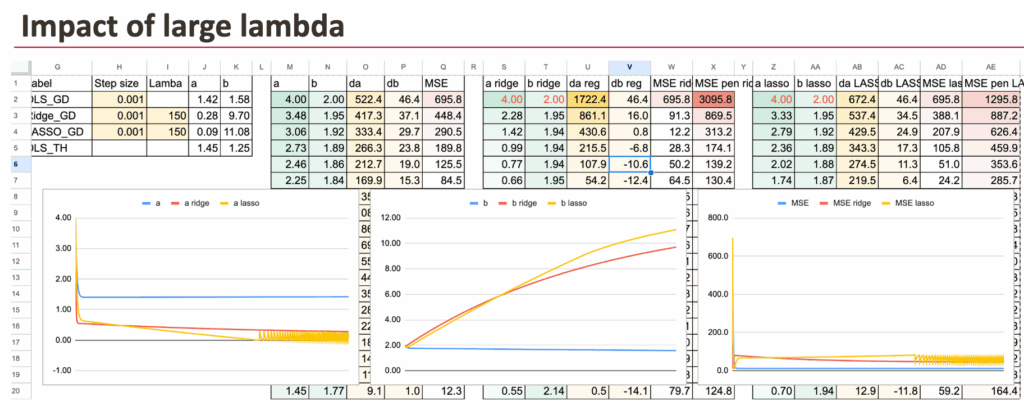
Now, we can visualize the coefficient a for all the three models. In order to see the differences, we input very large lambdas.
Impact of lambda
For large value of lambda, we will see that the coefficient a becomes small.
And if lambda LASSO becomes extremely large, then we theoretically get the value of 0 for a. Numerically, we have to improve the gradient descent.
Regularized Logistic Regression?
We saw Logistic Regression yesterday, and one question we can ask is if it can also be regularized. If yes, how are they called?
The answer is of course yes, Logistic Regression can be regularized
Exactly the same idea applies.
Logistic regression can also be:
- L1 penalized
- L2 penalized
- Elastic Net penalized
There are no special names like “Ridge Logistic Regression” in common usage.
Why?
Because the concept is no longer new.
In practice, libraries like scikit-learn simply let you specify:
- the loss function
- the penalty type
- the regularization strength
The naming mattered when the idea was new.
Now, regularization is just a standard option.
Other questions we can ask:
- Is regularization always useful?
- How does the scaling of features impact the performance of regularized linear regression?
A Unified View of Linear Models and Regularization
A more general view: changing the loss, not the model
We can actually go one step further.
Everything we discussed can be seen as a modification of the loss function.
By changing the loss, or by adding terms to it, we obtain different behaviors, and what we usually call “different models”.
From this point of view, Ridge, Lasso, and Elastic Net are not new models.
They are simply different ways of defining the objective we minimize.
This unified perspective is very explicit in scikit-learn.
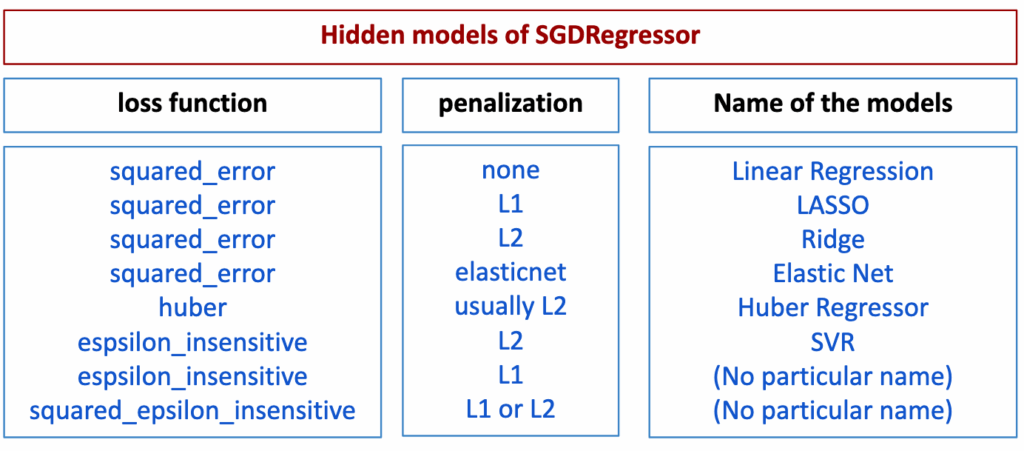
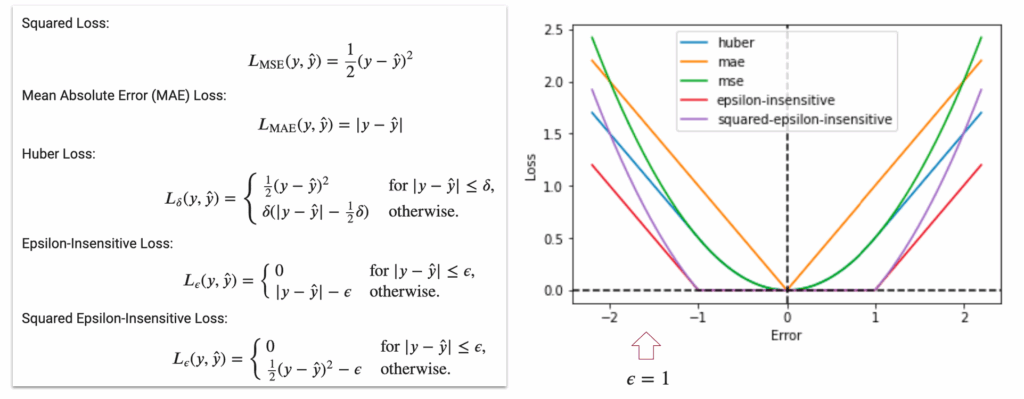
And these loss functions can be visualized as follows:
The estimator SGDRegressor is a good example: it centralizes multiple choices in a single object:
- the data-fit term (squared loss, Huber loss, epsilon-insensitive loss, etc.)
- the regularization type (none, L1, L2, Elastic Net)
- the regularization strength
In other words, we do not switch between “models”.
We switch between loss functions and penalties.
One model, many configurations
This naturally leads to the question:
Are linear regression, Ridge, and Lasso different models?
Or are they just different parameterizations of the same linear regressor?
The answer depends on perspective.
- From a historical or pedagogical perspective, they are often presented as separate models.
- From an optimization and implementation perspective, they are simply different configurations of the same linear model.
Same prediction function.
Same coefficients.
Different objective function.
Why this perspective is useful
I personally find this unified view much more clarifying.
It helps to understand that:
- the core model is linear regression
- regularization is not a new idea, but an additional constraint
- “choosing a model” often means “choosing a loss and a penalty”
Once you see things this way, Ridge and Lasso stop feeling special.
They become natural variations inside a single, coherent framework.
And that is often how they are implemented in practice.
Conclusion
Ridge and Lasso do not change the linear model itself, they change how the coefficients are learned.
By adding a penalty, regularization favors stable and meaningful solutions, especially when features are correlated. Seeing this process step by step in Excel makes it clear that these methods are not more complex, just more controlled.
One more thing…
Introducing a lambda already means one thing: scale matters.
Lambda is nothing more than a scaling factor that makes the penalty term comparable to the MSE.
But if scale matters between the data-fit term and the penalty, then it also matters inside the penalty itself.
The penalty is a kind of distance on the coefficient vector.
And just like any distance, it implicitly assumes that all dimensions are comparable.
If coefficients correspond to variables with different units or meanings, this assumption is questionable.
In that case, one could argue that each coefficient should have its own scaling factor inside the penalty, not just a single global lambda.
Seen this way, standard regularization is already a modeling choice about scale, not a neutral mathematical operation.
From a machine-learning point of view, all these choices simply become hyperparameters to tune.
Lambda is one hyperparameter that controls the global balance between the data-fit term and the penalty.
But once we accept that scale matters inside the penalty, we naturally introduce others:
- per-coefficient weights,
- group weights,
- or parameters that control how penalties are distributed across dimensions.
In that sense, standard regularization is just the simplest possible choice:
one global lambda, same penalty for everyone.
More refined regularization schemes do not change the model.
They only increase the number of hyperparameters that describe how we regularize.
And as with any hyperparameter, these choices are not decided by theory alone.
They are validated empirically, through cross-validation and out-of-sample performance.
So even this “scale issue” ultimately fits naturally into the machine-learning framework:
it is not a flaw of regularization, but a reminder that regularization itself is something to tune, not something to assume.